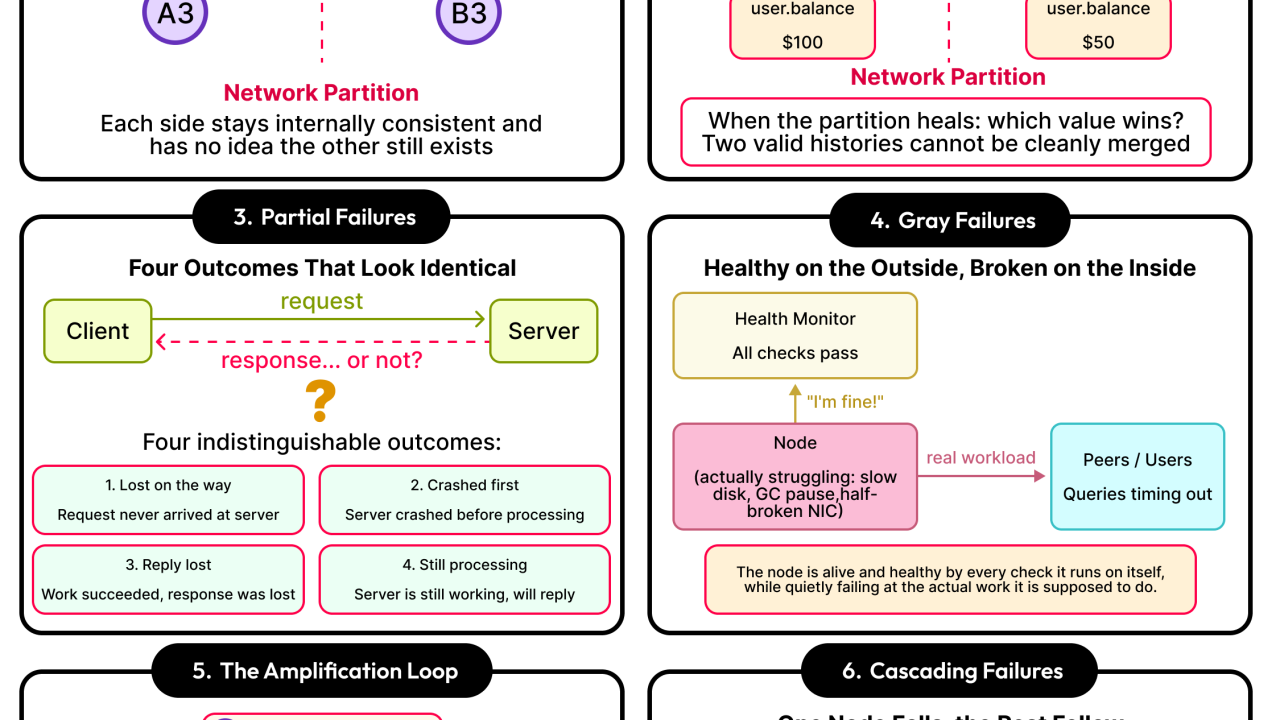
What is the interpretation of a distributed system being operational?. In a single machine environment, identifying the issue is straightforward as a program either executes without errors or has crashed, and the distinction is often evident from the stack trace. However, distributed systems do not share this simplicity.
Each server may indicate normality even though users are encountering issues. The entire system could be functioning correctly yet unable to recover independently from a situation it’s trapped in. It could continue to provide inaccurate information without raising any red flags.
This could be due to problems that aren’t necessarily software bugs. In distributed systems, there have been longstanding recurring failure patterns that persist across various systems. These patterns are known by name, have specific mechanisms, and standard methods of prevention.
This article will explore the most crucial failure mode patterns and the typical strategies to address them.


